이 글은 Real MySQL 8.0 책을 읽고 정리한 것입니다.
Real MySQL 8.0 1권
《Real MySQL》을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0의 GTID와 InnoDB 클러스터 기능들과 소프트웨어 업계 트렌드를 반영한 GIS 및 전문 검색 등의 확장 기능들을 추가로 수록했다.
www.aladin.co.kr
데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건일 때가 상당히 많다. 따라서, 이 장의 앞부분에서는 먼저 ‘랜덤 I/O’ 와 ‘순차 I/O’에 대해 설명하고자 한다.
8.1 디스크 읽기 방식
8.1.1 HDD와 SDD
SDD는기존 하드 디스크 드라이브에서 데이터 저장용 플래터(원판)를 제거하고 그 대신 ‘플래시 메모리’를 장착하고 있다. DRAM보다는 느리지만 HDD보다는 빠르다는 특성을 갖는다. 요즘은 DBMS용으로 사용할 서버에서 대부분 SDD를 채택하고 있다.

디스크의 헤더를 움직이지 않고 한 번에 많은 데이터를 읽는 순차 I/O에서는 SSD가 HDD보다 조금 더 빠르거나 비슷할 때도 있다. 하지만 SSD의 장점은 기존 HDD보다 랜덤 I/O에서 훨씬 빠르다는 것에 있다. DB 서버에서 순차 I/O 작업은 비중이 크지 않고, 랜덤 I/O를 통해 작은 데이터를 읽고 쓰는 작업이 대부분이므로 SSD의 장점은 DBMS용 스토리지에 최적이다.
8.1.2 랜덤 I/O와 순차I/O
‘랜덤 I/O’란, 하드 디스크 드라이브의 플래터(원판)를 돌려서, 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음, 데이터를 읽는 것을 말한다. 순차 I/O와 랜덤 I/O의 작업 과정은 동일하지만 동작 횟수에서 차이가 난다.

디스크의 플래터는 위와 같이 여럽 겹이 쌓여져서, 한 번에 ‘읽기’ 동작으로 각 원판들의 동일한 부분들을 동시에 읽어들일 수 있다. 예를 들어, 3개의 데이터를 읽는 것을 가정할 때, 순차 I/O에서 1번의 시스템콜 호출이 필요한 반면, 랜덤 I/O는 3번의 시스템콜 호출이 필요할 수 있다.
디스크에 데이터를 쓰고 읽는 데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉, 디스크의 성능은 디스크 헤더의 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 의해 결정된다.
랜덤 I/O는 순차 I/O보다 더 많은 디스크 헤더의 이동을 요구하기 때문에, 상대적으로 더 느리다. SSD 드라이브에서도 랜덤 I/O는 순차 I/O보다 전체 스루풋이 떨어진다. 따라서, DB서버에 SSD를 사용한다고 해서 랜던 I/O가 주는 영향력을 줄이는데 한계가 있다.
위와 같은 랜덤 I/O를 줄이는 것인 쿼리 튜닝의 주된 목적이다. 여기서 랜덤 I/O를 줄인다는 의미는, 순차 I/O로 바꿔서 실행한다는 의미가 아니라, 반드시 필요한 데이터만 읽도록 쿼리를 개선한다는 의미이다.
8.2 인덱스란?
인덱스란 DB에 저장된 레코드를 빠르게 찾아내기 위해 사용되는 자료구조이다. 컬럼(또는 컬럼들)의 값과 해당 레코드가 저장된 주소를 key-value 쌍으로 저장하여 인덱스를 생성할 수 있다. 인덱스는 컬럼의 값을 주어진 순서대로 미리 정렬해서 보관한다. 또한, 데이터가 새롭게 추가된 이후에도 항상 정렬된 상태를 유지하는 자료 구조이다. 프로그래밍 언어의 SortedList와 동일하다고 생각하면 된다.
SortedList 자료 구조는 데이터가 저장될 때마다 항상 값을 정렬해야 하므로 저장 과정이 복잡하고 느리지만, 이미 정렬돼 있는 상태라서 데이터를 검색할 때는 매우 빠르게 찾을 수 있다. DBMS의 인덱스도 동일하게 DML(INSERT, UPDATE, DELETE)구문에서는 느리게 동작하지만, SELECT구문에서는 빠르게 동작하는 것이 이와 동일하다.
결론적으로, DBMS에서 인덱스는 데이터의 저장 성능을 희생하고 그 대신 데이터의 읽기 속도를 향상시키는 기능이다. 인덱스를 설정할 때는, 데이터의 저장 속도를 어디까지 희생할 수 있고, 읽기 속도는 얼마나 더 빨라야 하는 지를 우선적으로 결정해야 한다.
인덱스를 ‘역할’ , ‘데이터 관리 방식(알고리즘)’ , ‘중복 값 허용’ , ‘기능’ 으로 구분할 수 있다.
역할
- 프라이머리 키(인덱스) : 레코드를 대표하는 컬럼으로 만들어진 인덱스. NULL 값을 허용하지 않으며, 중복을 허용하지 않음.
- 세컨더리 키(인덱스) : 세컨더리 인덱스가 유니크 인덱스일 경우 대체키로 보기도 함.
데이터 저장 방식(알고리즘)
- B-Tree 인덱스 : 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘.
- Hash 인덱스 : 컬럼의 값으로 해시값을 계산해서 인덱싱하는 알고리즘. 매우 빠름. 값을 변형했기 때문에, 값의 일부만 검색하거나 범위 검색을 수행할 때는 사용할 수 없음.
데이터의 중복 허용 여부
- 유니크(Unique) 인덱스 : 유일한 값이 오직 1개만 존재. 옵티마이저에 동작에 큰 영향을 줌.
- 유니크하지 않은(Non-Unique) 인덱스 : 중복된 값 존재 가능.
기능
- 전문 검색용 인덱스
- 공간 검색용 인덱스
8.3 B-Tree 인덱스
B-Tree 인덱스는 DB에서 범용적인 목적으로 가장 많이 쓰이는 알고리즘이다. B-Tree에서 B는, Binary(이진)의 약자가 아닌, Balanced의 약자임을 유의해야 한다. B-Tree는 컬럼의 원래 값을 변형시키지 않고, 인덱스 구조체 내에서 항상 정렬된 상태를 유지한다. 전문 검색과 같은 특수 목적이 아니라면, B-Tree 인덱스는 일반적인 용도에 가장 적합하다.
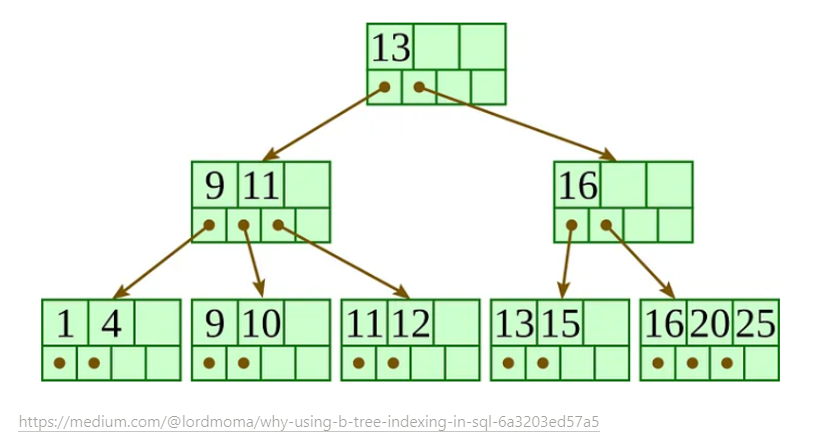
8.3.1 구조 및 특성
B-Tree의 구성요소는 아래와 같다.
- 루트 노드 : 트리구조 최상위의 하나의 노드. 자식노드 주소가 담김.
- 브랜치 노드 : 루트 노드도 아니고 리프 노드도 아닌 중간 노드. 자식노드 주소가 담김.
- 리프 노드 : 가장 하위에 있는 노드. 실제 데이터 레코드를 찾아가기 위한 주소값이 담김.
인덱스의 키 값은 모두 정렬된 상태로 존재하지만, 데이터 파일의 레코드는 정렬돼 있지 않고 임의의 순서로 저장된다. DBMS에서는 레코드가 삭제된 이후, 새로운 레코드가 추가되면, 이전에 삭제된 레코드의 공간을 재사용하도록 설계되있다. 따라서, DBMS에서 테이블은 INSERT된 순서로 저장되는 것은 아니다.
다만, InnoDB 테이블에서 레코드는 클러스터되어 디스크에 저장되므로 기본적으로 프라이머리 키 순서로 정렬되어 저장된다.
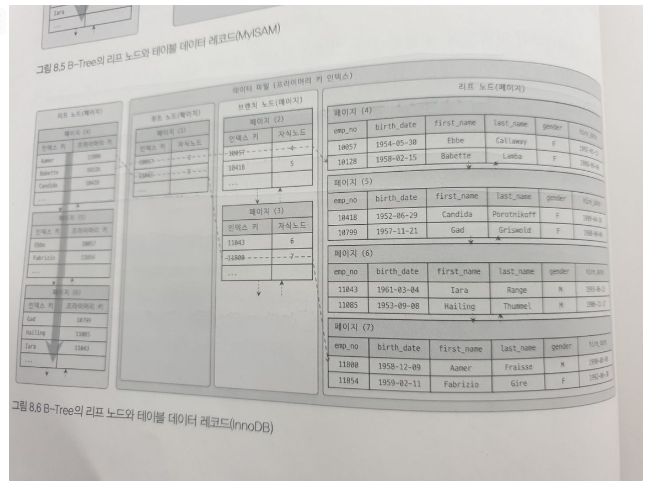
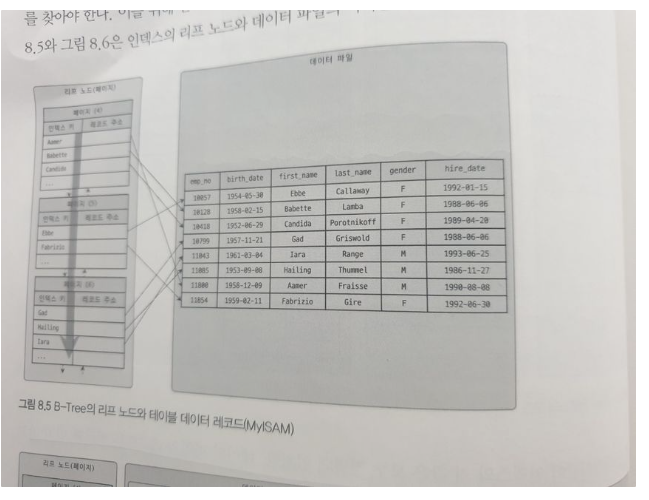
인덱스는 테이블의 키 컬럼만 갖고 있으므로, 나머지 컬럼을 읽으려면 데이터 파일에서 해당 레코드를 찾아야 한다. 이러한 점은 InnoDB와 MyISAM 엔진모두 동일한데, 주요한 차이점은 세컨더리 인덱스를 통해 데이터 파일의 레코드를 찾아가는 방법에 있다. MyISAM에서 세컨더리 인덱스는 레코드가 저장된 실제 물리적인 주소를 가지고 있는 반면, InnoDB에서는 세컨더리 인덱스가 프라이머리 키를 레코드의 주소처럼 사용한다.
이러한 InnoDB의 특징 때문에, 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해서는 반드시 프라이머리 키를 저장하고 있는 B-Tree를 다시 한번 검색해야 한다.(상단 좌측 이미지)
8.3.2 B-Tree 인덱스 키 추가 및 삭제
1. 인덱스 키 추가
새로운 키 값이 B-Tree에 저장될 때 테이블의 스토리지 엔진에 따라 즉시 인덱스에 저장될 수도 있고 아닐 수도 있다. MyISAM과 Memory 엔진의 경우 바로 저장되지만, InnoDB의 경우에는 기본 키는 바로 저장되고, 아닐 경우 인덱스 저장을 지연시킬 수도 있다.
새로운 인덱스 키값이 추가되면, B-Tree 에 저장할 적절할 공간을 찾고, 레코드의 키 값과 주소 정보를 리프 노드에 저장하게 된다. 인덱스에 저장된 키들이 정렬을 유지해야 되기 때문에, 레코드 추가 비용이 '1'이라고 가정하면, 인덱스 키 추가는 '1.5' 정도의 비용을 요구한다.
2. 인덱스 키 삭제
B-Tree의 키 값 삭제는 간단하게, 리프 노드를 찾아서 삭제 마크만 하면 작업이 완료된다. 인덱스 키 추가의 경우와 마찬가지로, 스토리지 엔진에 따라, 실제 삭제가 되는 순간은 달라질 수 있다.
3. 인덱스 키 변경
인덱스의 키 값은 그 값에 따라 저장될 리프 노드의 위치가 결정되므로 B-Tree 키 값이 변경되는 경우에는 단순히 인덱스상의 키 값만 변경하는 것은 불가능하다. B-Tree의 키 값 변경 작업은 먼저 키 값을 삭제한 후, 다시 새로운 키 값을 추가하는 형태로 진행된다.
4. 인덱스 키 검색
- 루트 노드 → 브랜치 노드 → 리프 노드 순으로 트리 탐색
- SELECT뿐만 아니라, UPDATE or DELETE를 수행할 때도 사용됨
- B-Tree를 이용한 검색은, 100% 일치하거나, 값의 앞부분만 일치할 경우에 사용 가능
- 키 값의 뒷부분만 검색하는 용도로는 사용 불가능
- 인덱스의 키 값을 함수 or 연산을 통해 변형한 이후에는 인덱스 사용 불가능
- UPDATE or DELETE 수행 시, 적절한 인덱스가 없다면 테이블 전체를 잠글 수 있음(유의사항)
8.3.3 B-Tree 인덱스 사용에 영향을 미치는 요소
1. 인덱스 키 값의 크기
- 요약 : 인덱스 키 값의 크기는 가능하면 작게 만드는 것이 좋다.
InnoDB 스토리지 엔진은 데이터를 페이지라는 기본단위에 저장하여 관리한다. 인덱스도 동일하게 페이지 단위로 관리되며(버퍼 풀에 저장) 루트 노드, 브리지 노드, 리프 노드 모두 페이지에 저장된다.
MySQL에서 B-Tree의 자식 노드를 몇 개까지 가질 수 있는 지는, 인덱스의 페이지 크기와 키 값의 크기로 결정된다. 인덱스 페이지 크기의 기본값은 16KB이다. 만약, 16KB의 페이지에 ‘16B(키 값의 크기) + 12B(자식 노드 주소 크기)’의 키가 저장된다고 했을 때, 16 * 1024 / 30 = 585개의 키가 저장될 수 있다. 키 값의 크기를 16B → 32B로 늘릴 경우, 16 * 1024 / 44 = 372개의 키가 저장될 수 있다.
만약, 500개의 범위에 해당하는 레코드를 위 인덱스를 통해 조회하고자 할 때, 전자는 디스크에서 인덱스 페이지를 1번만 읽어오면 되지만, 후자는 2번 읽어와야 한다. 따라서, 더 느릴 것이다.
정리하자면, 인덱스 키 값의 크기와 한 페이지에 저장할 수 있는 인덱스 키의 개수는 반비례한다. 인덱스 키 값의 길이가 길어진다는 의미는 인덱스의 크기가 커진다는 의미이며, InnoDB 버퍼 풀의 사이즈는 제한되있기 때문에, ‘조회’를 수행하기 위해 여러 페이지를 조회해야 할 수도 있다. 인덱스 키 값의 크기를 키울 경우, 조회 성능일 떨어질 수 있다.
2. B-Tree 깊이
B-Tree 인덱스의 깊이를 직접 제어할 방법은 없다. B-Tree의 깊이는 MySQL에서 값을 검색할 때 몇 번이나 랜덤하게 디스크를 읽어야 하는지와 관련된 문제이다. 인덱스 키 값이 커지면, 한 페이지에 담을 수 있는 인덱스의 키 개수가 줄기 때문에, 여러 페이지를 조회해야하며, 이는 디스크 읽기 회수를 늘린다. 즉, B-Tree 깊이가 깊어지면 조회 성능이 떨어진다.
3. 선택도(기수성)
선택도(기수성)은 모든 인덱스 키 값 가운데 유니크한 값을 의미한다. 유니크한 값이 많아질 수록(선택도가 높을 수록) 검색 대상이 줄어들 기 떄문에 그만큼 빠르게 처리된다.
예를 들어, 10000개의 레코드를 담은 테이블에 대한 조회를 수행한다 가정했을 때, 10개의 선택도와 1000개의 선택도를 비교하면, 1000개의 선택도에서는 10개의 레코드에 대해서만 조회하면 되기 때문에, 더 빠르게 처리될 것이다.
4. 레코드의 건수
테이블의 전체 레코드에 대한 조회 연산을 수행할 때, 전체 테이블을 읽어 필요없는 부분을 제외하는 것이 효율적일지, 인덱스를 통해 필요한 레코드만 읽어들이는 것이 효율적일지 판단해야 한다. MySQL에서는 인덱스로 1개의 레코드를 읽을 때의 비용을, 인덱스 없이 1개의 레코드를 읽을 때의 비용보다, 4.5배 정돋 많은 것으로 예측한다. 따라서, 인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 사용하지 않고 테이블을 모두 읽어들인 다음에 필터링을 수행하는 것이 더 효율적이다.
8.3.4 B-Tree 인덱스를 통한 데이터 읽기
1. 인덱스 레인지 스캔
- 인덱스에서 조건을 만족하는 값 찾기
- 1번에서 탐색된 위치부터 필요한 만큼 인덱스 쭉 읽기
- 2번에서 읽어들인 인덱스의 키와 레코드 주소를 활용해, 실제 레코드가 저장된 페이지를 가져와서, 최종 레코드 읽어들이기
인덱스 레인지 스캔은 검색해야할 인덱스의 범위가 결정됐을 때 사용하는 방식이다. 리프 노드 → 브리지 노드 → 리프 노드 순으로 탐색해야 검색을 시작할 위치를 찾는다. 이후 리프 노드의 레코드를 순서대로 읽는다. 만약, 탐색을 이어가야 하는데, 리프 노드의 끝에 도달할 경우, 리프 노드간의 링크를 타고 다음 리프 노드로 넘어가서, 탐색을 이어간다. 다만, 여기까지 설명한 것은 인덱스 페이지 상에서의 탐색을 말한 것이고, 테이블에서 실제 레코드를 가져오는 과정이 추가될 수 있다.
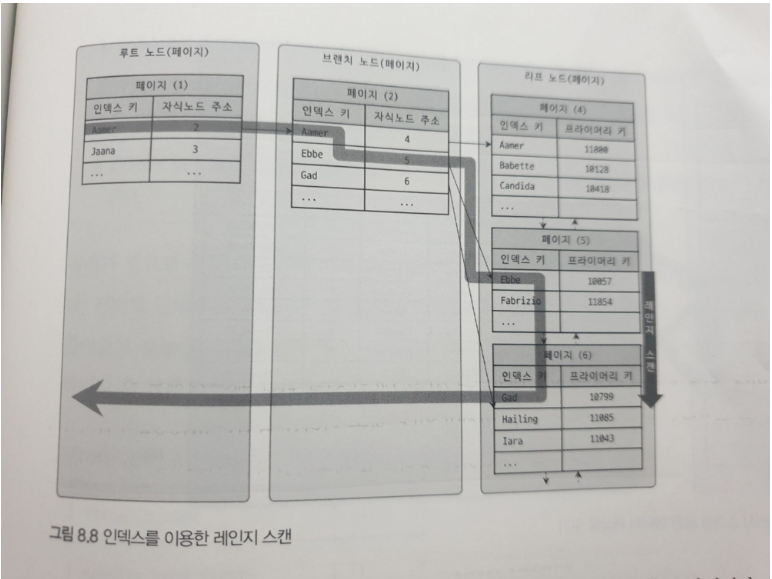
데이터 파일에서 테이블의 레코드를 가져오는 동작을 수행할 때, 리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어온다. 레코드 한 건 한 건 단위로 랜덤 I/O가 한번씩 수행된다. 이 때문에 인덱스를 사용한 조회가, 없이 조회할 때보다 더 많은 비용이 드는 것이다(동일한 개수의 레코드들 기준).
-- 예시 : 인덱스 레인지 스캔
mysql> explain select * from city where (100 < id) and (id < 200)\\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 99
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
2. 인덱스 풀 스캔
“인덱스 풀 스캔일 경우 인덱스를 탄다고 표현하지 않는다.”
인덱스 레인지 스캔과 달리 인덱스의 처음부터 끝까지 모두 읽는 방식을 말한다. 일반적으로 인덱스의 크기는 테이블의 크기보다 작으므로 직접 테이블을 처음부터 끝까지 읽는 것보다 인덱스만을 읽는 것이 효율적이다. 왜냐하면, 더 적은 디스크 I/O로 쿼리를 처리할 수 있기 때문이다. 다만, 인덱스에 명시된 컬럼 이외의 다른 컬럼을 필요로 하여, 데이터 레코드를 읽어야 될 경우, 인덱스 풀 스캔을 사용해서는 안된다.

-- 테이블 풀 스캔
mysql> explain select * from city;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4047
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 sec)
-- 인덱스 풀 스캔
mysql> explain select count(*) from city\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: index
possible_keys: NULL
key: CountryCode
key_len: 12
ref: NULL
rows: 4047
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
3. 루스 인덱스 스캔
루스 인덱스 스캔은 인덱스 레인지 스캔과 비슷하게 작동하지만 중간에 필요치 않은 인덱스 키 값은 무시(SKIP)하고 다음으로 넘어가는 형태로 처리된다. 일반적으로 GROUP BY 또는 MIN, MAX를 최적화하는데 사용된다.
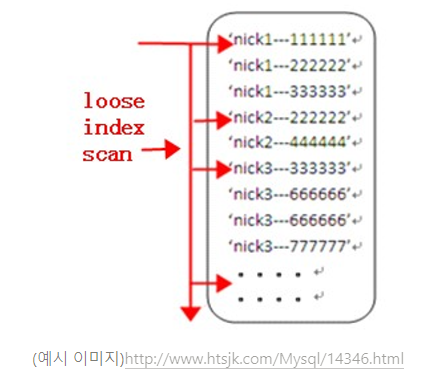
mysql> SELECT dept_no, MIN(emp_no)
-> FROM dept_emp
-> WHERE dept_no BETWEEN 'd002' AND 'd004'
-> GROUP BY dept_no;
+---------+-------------+
| dept_no | MIN(emp_no) |
+---------+-------------+
| d002 | 10042 |
| d003 | 10005 |
| d004 | 10003 |
+---------+-------------+
3 rows in set (0.01 sec)
mysql> EXPLAIN SELECT dept_no, MIN(emp_no)
-> FROM dept_emp
-> WHERE dept_no BETWEEN 'd002' AND 'd004'
-> GROUP BY dept_no;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: dept_emp
partitions: NULL
type: range
possible_keys: PRIMARY,ix_fromdate,ix_empno_fromdate
key: PRIMARY
key_len: 16
ref: NULL
rows: 4
filtered: 100.00
Extra: Using where; Using index for group-by
1 row in set, 1 warning (0.00 sec)
4. 인덱스 스킵 스캔
인덱스 스킵 스캔은 옵티마이저가 다중 컬럼으로 생성된 인덱스에 대해, 인덱스에 포함된 하나의 컬럼만으로도 인덱스 검색을 가능하게 해주는 기능이다(MySQL 8.0 부터 도입). 이 기능을 사용하려면, 옵티마이저의 ‘skip_scan’ 기능을 활성화해야 한다.
mysql> set optimizer_switch = 'skip_scan=off';
Query OK, 0 rows affected (0.00 sec)
mysql> explain select gender, birth_date from employees where birth_date >= '1965-02-01';
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: index
possible_keys: NULL
key: ix_gender_birthdate
key_len: 4
ref: NULL
rows: 300778
filtered: 33.33
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
위 쿼리는, skip_scan을 off한 상황에서는, 쿼리 실행시 풀 인덱스 스캔(type=index) 방식으로 동작하고 있다.
mysql> set optimizer_switch = 'skip_scan=on';
Query OK, 0 rows affected (0.00 sec)
mysql> explain select gender, birth_date from employees where birth_date >= '1965-02-01';
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: ix_gender_birthdate
key: ix_gender_birthdate
key_len: 4
ref: NULL
rows: 100249
filtered: 100.00
Extra: Using where; Using index for skip scan
1 row in set, 1 warning (0.00 sec)
skip_scan을 on한 이후에는, 쿼리 실행시 인덱스 스킵 스캔(type=index , Extra=’~ skip scan’) 방식으로 동작한다.
다만, 인덱스 스킵 스캔 기능을 사용하려면 아래의 조건을 만족해야 한다.
- WHERE 조건절에 조건이 없는 인덱스의 선행 컬럼의 유니크한 값의 개수가 적어야 함. 이래야 인덱스 스킵 스캔을 사용하는 의미가 있다.
- 쿼리가 인덱스에 존재하는 컬럼만으로 처리 가능해야 함(커버링 인덱스)
8.3.5 다중 컬럼(multi-column) 인덱스
두 개 이상의 컬럼으로 구성된 인덱스를 ‘다중 컬럼 인덱스’라고 부른다. 다중 컬럼 인덱스에서 핵심적으로 알아야 할 사항은, 뒤에 있는 컬럼은 앞에 있는 컬럼에 의존해서 정렬된다는 것이다.
| dept_no | emp_no |
| 1 | 1045 |
| 1 | 1046 |
| 1 | 1021 |
| 2 | 1024 |
| 2 | 1056 |
| 2 | 1063 |
| 3 | 1003 |
위 표에서 보면, 맨 뒤에있는 키의 emp_no는 1003으로 emp_no 중에서 가장 작은 값임에도 불구하고, 인덱스의 맨 뒤에 놓인다. 그 이유는 emp_no는 dept_no가 먼저 정렬된 이후, 정렬되기 때문이다. 다중 컬럼 인덱스에서는 인덱스 내에서 각 컬럼의 위치(순서)가 상당히 중요하며, 신중하게 결정해야 한다.
'CS > 데이터베이스' 카테고리의 다른 글
| [DB] 정규화 (1) | 2024.02.01 |
|---|---|
| [DB] SQL - JOIN (1) | 2024.01.23 |
| [DB] Real MySQL 8.0 - 4.2 InnoDB 스토리지 엔진 아키텍처 (2) | 2024.01.22 |
| [DB] SQL 질문 정리 (0) | 2024.01.18 |
| [DB] SELECT 문장 처리 순서 (2) | 2024.01.18 |



